
In ambiente GIS, quando si parla di raggruppare oggetti – clustering – è implicito farlo secondo una logica spaziale (giustamente). Tuttavia, spesso è ugualmente importante considerare gli attributi, soprattutto quando la posizione di un oggetto gioca un ruolo minore nel tipo di raggruppamento.
In questo post vedremo come utilizzare il plugin di QGIS Attribute based clustering sviluppato da Eduard Kazakov, per organizzare delle campagne di monitoraggio di zone che presentano una superficie molto variabile.
L’ obiettivo sarà quello di raggruppare le aree in modo da uniformare le campagne di monitoraggio, ovvero ripartire equamente l’area totale da monitorare nelle diverse giornate.


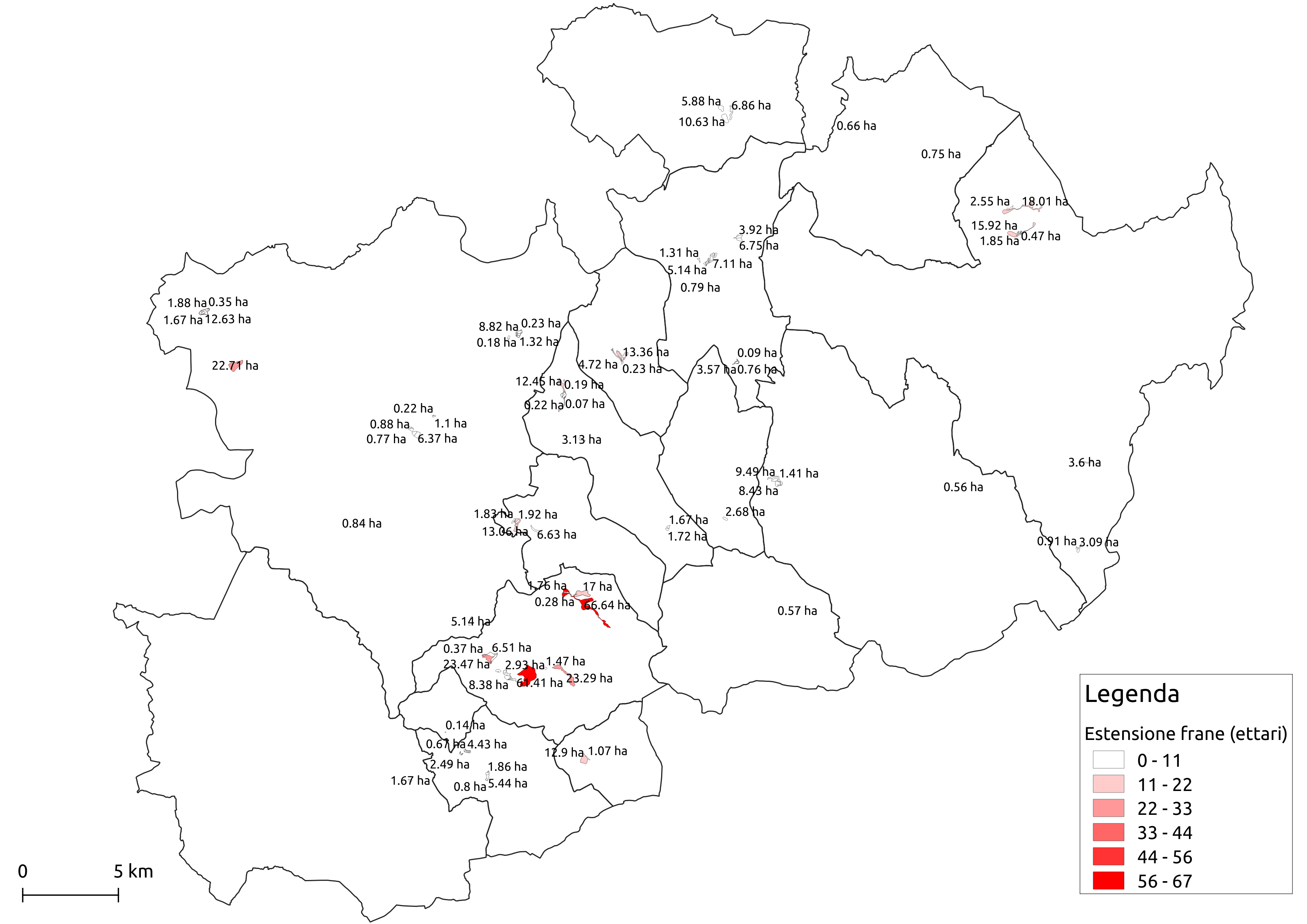
Di seguito sono riportate le distribuzione delle superfici.


Dai grafici è possibile notare che esistono due frane significativamente più estese delle altre (>60 ettari), un gruppo ristretto di frane con un estensione media (tra 10 e 25 ettari) mentre la maggior parte delle frane, sparse su tutto il territorio, presenta un estensione minore (<10 ettari).
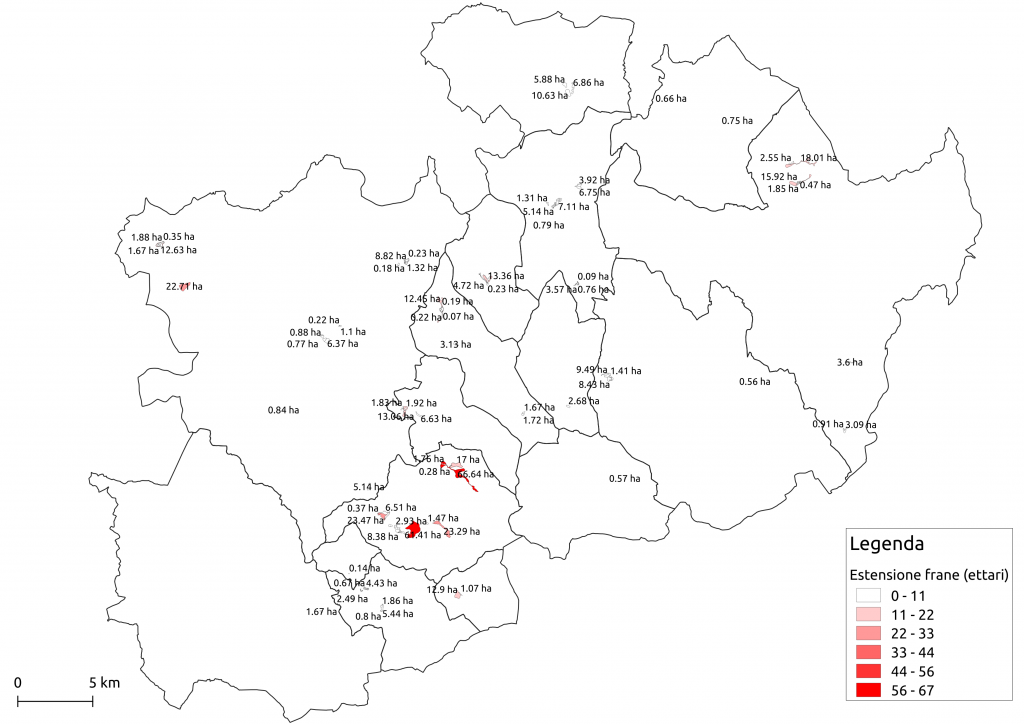
Il plugin presenta quattro metodi di raggruppamento, due varianti di K-Means e due di clustering gerarchizzato. Indipendentemente dall’algoritmo utilizzato, il risultato sarà un nuovo campo nella tabella degli attributi con l’identificativo numero del cluster a cui appartiene l’oggetto. Il clustering gerarchizzato è nativo e non richiede librerie aggiuntive, mentre K-Means richiede che la libreria SciPy sia installata. Inoltre, è possibile calcolare le distanze di ciascun oggetto rispetto al centroide del cluster a cui appartengono e salvarle come attributi.
La tecnica di raggruppamento più semplice è il clustering gerarchizzato. Consiste nella formazione di gruppi associando sequenzialmente oggetti vicini tra loro, dove per decidere quali gruppi formare è necessario definire una misura di dissimilarità. Nella maggior parte dei metodi di clustering gerarchizzato si fa uso di metriche specifiche (es. distanza euclidea) che quantificano la distanza tra coppie di elementi e di un criterio di collegamento che specifica la dissimilarità di due insiemi di elementi (cluster) come funzione della distanza a coppie tra elementi nei due insiemi. Il risultato del calcolo è una matrice delle distanze. Oggetti simili rispetto all’attributo preso in considerazione saranno quindi combinati in un unico gruppo.
L’ interfaccia grafica è molto semplice. L’ utente seleziona il layer vettoriale, specifica l’attributo (numerico) che sarà utilizzato come parametro di raggruppamento e conferisce ad esso un peso quando necessario. Si sceglie quindi il metodo di raggruppamento, il numero dei gruppi da costituire, il nome della nuova variabile e si indica se normalizzare i valori dei parametri.
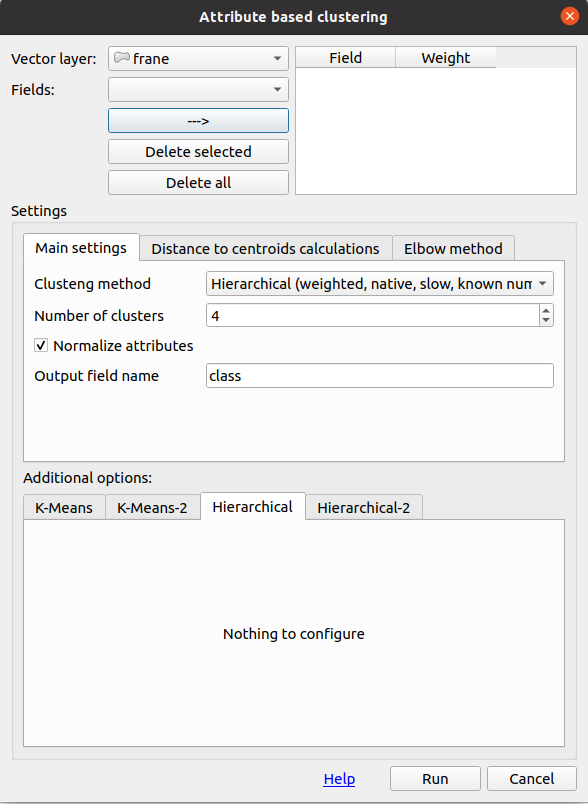
Utilizzando l’algoritmo di clustering gerarchizzato, imposto un raggruppamento in 6 classi. Il risultato è un nuovo attributo che contiene il numero del cluster per ogni oggetto. Così sarà possibile customizzare lo stile per una visualizzazione immediata.
Lascia un commento
Devi essere connesso per inviare un commento.